
OS_ch4_Process
1. Process State
1) 프로세스: 실행중인 프로그램. 프로세스 수행은 순차진행임
- CPU가 컨트롤을 넘겨주면 그제서야 active process가 됨
- program counter, stack, data section을 가지고 있음(address space)
2) 프로세스의 상태
- new: 생성됨
- running: 실행중
- waiting: I/O job으로 인해 waiting queue에 줄섬
- ready: running 전의 아이들. 스케줄러가 골라서 running 시켜줌
- terminated: 프로세스 종료
3) 프로세스 상태 천이
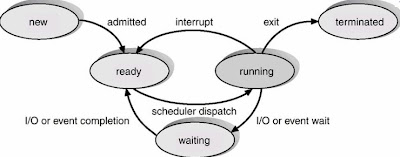
- new->ready: long term scheduler가 뽑아서 줄세워줌
- ready->running(dispatch): 스케줄러가 선택해줌
- running->waiting(sleep): I/O 들어옴
- running->ready(save): time quantum 끝남
- waiting->ready: I/O 처리 끝났음. 다시 줄 서러감(disk interrupt 처리했단 의미)
- running->terminated: 프로세스 처리 다 끝남. out
- ready에도, waiting 에도 queue있다.
*Computation: CPU bound job, CPU burst 예를 들면 compile, 무한loop등
I/O: I/O bound job, I/O burst. 예를들면 DB작업 등
2. PCB(Process Control Block)
1)프로세스들은 아래 정보들을 가지고 있따!
- process state: 상태값
- program counter: 현재 어디 수행중이니?
- CPU registers: 32개?
* CPU reg 꼭 필요한것? stack/program counter/accumulator
- CPU 스케줄링 정보
- 메모리 관리 정보
- 과금 정보(유료일때 ㅋㅋ)
- I/O 상태정보: file pointer 관리 등

2) PCB 는 어디에 보관?? -> kernel 자료구조 BSS에 보관한다.
- 앞 뒤 PCB 정보를 linked list 형태로 가지고 있다.
3) CPU Switch:
- CPU bound job을 하다가 I/O를 만나면?(왜만나니? 코드를 그렇게 짰으니까-_-) interrupt나 system call을 한 뒤
PCB에 상태 저장하고 다른애 상태 불러와서 다른애 프로세스 수행한다. 다른애도 I/O 만나면 똑같이 자기 상태 저장하고 다른애 상태 불러와서 또 진행~
PCB에 상태 저장하고 다른애 상태 불러와서 다른애 프로세스 수행한다. 다른애도 I/O 만나면 똑같이 자기 상태 저장하고 다른애 상태 불러와서 또 진행~
4) Process Scheduling Queues
- Job queue: 프로세스가 생성되면 무조건 줄섬
- Ready queue: 메인 메모리에 올라와있는 애들. long-term scheduler가 뽑아준 애들
- Device queue: I/O를 기다리고 있는 프로세스들이 줄선 큐. 디바이스마다 큐 있다. 한 디바이스마다 PCB들 줄서있음
* ready 되면 하드디스크->메인 메모리로 들어옴: swap in
waiting 되거나 다른 상태되면 하드디스크로 쫓겨남: swap out
3. Scheduler
1) long-term scheduler: 레디큐에 들어올 애들 뽑음, 느림, multiprogramming
short-term scheduler: 레디큐 애들 중에 running 시킬 애 뽑음, 빠름, multitasking
medium-term scheduler: I/O 길어서 하드디스크로 쫓겨난(swap out) 애들 다시 레디큐에 올려줌
(waiting queue에 있는 올려주는 것과 다름)
(waiting queue에 있는 올려주는 것과 다름)
- 스케줄러 실행되는 경우: 프로세스가 생성/종료 되거나 I/O 가 시작되거나 끝났거나
2) Context Switching
- PCB,reg 등 바꿔치기함
- 전 프로세스의 상태를 저장하고 새 프로세스의 상태를 로딩하는 과정
- process 바꿔치기는 scheduling 하는 시간에 이루어짐
- overhead는 작을수록 좋다. 사실 안할수록 좋다.
* 우선순위 우선정책: 항상 좋은 것은 아님. CPU 차지하고 돌면 우선순위 내려버리고 오래 레디큐에서 기다린 애들은 우선순위 올려준다(aging). 따라서 공정하다!(중요한 정책임)
4. Process Creation
1) fork()
- 부모는 자식을 생성할 수 있다.
- fork(). exec()
- 부모와 자식은 자원 공유를 할 수 있음.
- 부모와 자식 병렬(concurrency)수행 가능
- 반드시 자식이 먼저 죽고 부모다 죽어야함(자식 컨트롤을 해야함. 안그럼 고아된다..)
2) 새 프로세스를 생성
- 일단 fork()로 복제 프로세스를 만들고(부모와 완전히 똑같음 심지어 program counter까지도)
- exec()으로 덮어씌움 -> 새로운 프로세스 생성!!
- 프로세스를 왜 생성하지?
- 유저가 로그인함(서비스 제공해줘야함)
- 유저가 프로그램을 실행했음
- os 서비스(프린터 등 데몬)
- 다른 프로세스 도우려고
3) 프로세스의 죽음: 코드 마지막줄 수행하고 죽음 ㅂㅂ. but! 자식 기다리고 죽는다. 만약 부모가 죽으면 자식은 stop
*program 자연현상 ㅋㅋ: locality of reference와 program cycle(CPU-I/O)
5. Producer and Consumer Problem: thread로 구현
1) Producer: 언제까지하나? 언제 sleep 해야하나?
- input 할 data가 없을 때
- input 할 공간이 없을 때
- 동작: 버퍼가 꽉 차 있으면 아무것도 안하고 무한루프 돌다가, 버퍼가 비게되면 상품 넣고 상품 수 증가시킴
2) Consumer: 언제까지 하나? 언제 sleep 해야하나?
- output 할 data가 없을 때
- quantum time이 없을 때
- 동작: 버퍼가 비어있으면 아무것도 안하고 무한루프 돌다가, 버퍼가 차게되면 상품 사고 상품 수 감소시킴
6. IPC(inter process communication)
1) direct: send, receive
2) indirect: mailbox
7. Synchronization and Buffer
1) Big buffer: asynchronous, indirect
2) Small buffer: synchronous, direct
8. RPC: 네트워크 시스템 위의 프로세스들 간 프로시져콜을 추상화함
1) Stub: 서버의 실제 프로시져를 불러내기 위한 클라이언트-side 프록시
- 클라이언트쪽: marshalls parameters
- 서버쪽: unpack marshalled parameters, 그리고 프로시져 수행
2) 수행 과정:
- 유저가 system call로 kernel을 불러서 프로시져 X에게 RPC메시지를 보내라고 함
- kernel이 포트 번호를 찾기위해 서버의 matchmaker에게 메시지를 보냄
- 서버의 matchmaker가 메시지를 받고서 포트번호p를 클라이언트에게 알려줌
- kernel은 포트번호 p에 유저의 RPC메시지를 매핑시키고 서버에게 RPC를 보냄
- 서버의 데몬이 메시지를 듣고 프로시져 수행 후 결과를 보내줌
- kernel이 결과를 받고 user에게 넘겨줌
3) Marshalling Parameters
- 클라이언트에서 서버로 함수 실행해달라고 요청할 때 parameter를 marshalling 해서 보낸다(packing)
- 서버단은 unmarsharlling 해서 parameter를 받는다
4) RPC에서 알아야 할 4가지!!
- stub
- skeleton(server side stub)
- pack/unpack
- marshalling/unmarshalling
-
4)
댓글남기기