
Hidden Markov Model (HMM) - 2
http://cheezestick.blogspot.kr/2012/09/hidden-markov-model-hmm.html
출처 :
3.2.1 Forward Algorithm


마지막 결과에 대해서는 output이 없기 때문에 algorithm은 termination을 고려 해 주어야 한다. (무한루프에 빠지지 않고 알고리즘을 끝내기 위해서.)
3.2.2 Backward Algorithm

* 초기 상태까지 와봐야 중간단계의 상태를 결정 할 수 있다. 즉 전체 t = 1,2,...,T-1, T 의
model parameter는 최종 단계 까지 알고리즘이 진행해야 알 수 있다.
(뒤에 나오는 viterbi algorithm에서는 최적의 path를 구하기 위해 path back tracking을 한다)
이러한 방법으로 우리는 output sequence의 확률을 state sequence를 이용해 나타내었다.
이제 이렇게 정의된 output sequence로부터 가장 그럴듯한 state sequence를 구해보자.

풀어야 하는 문제는 state 확률을 최대화 하는 Q*를 구하는 것이다.
이 문제를 해결하는데 가장 잘 알려진 알고리즘이 바로 viterbi algorithm이다.
단순하게 생각하면 시간 t의 여러개의 상태에서 시간 t+1의 어떤 상태 q(j)로 오는 path는 상태의 숫자만큼 존재한다. 그런데, 여러개의
path에서 어떤 path로 오는 것이 가장 그럴듯 한가? 라는 문제를 생각해 보면, 아래와 같이 두가지를 고려해야 한다.
1. t의 어떤 상태에서 t+1의 상태 q(j)로의 전이 확률 : a(i,j)
2. q(j)에서 관측된 output x(t+1)의 확률 : b(j, x(t+1))
즉, 이 두가지 확률을 곱한 값이 최대가 되는 path를 선택하면 된다.
이 문제를 DP 문제로 확대시켜서 수학적 귀납법으로 표현하면 아래와 같이 되는 것이다.
(사실 직관적으로 생각하면 두 확률을 곱한 확률이 최대가 되는 것이 최적의 path가 될것이라고 생각 할 수는 있겠는데... 명확하게 이해 하기는 어려웠다...)
물론 아직 HMM이 모델화 된 것이 아니기 때문에 Model parameter a(i,j), b(j, x(t+1))는 unknown 값이다. 이 값들은 나중에 EM Algorithm으로 estimation 해 낼 것이다.
3.2.3 viterbi algorithm
: hidden states의 가장 가능성 높은 sequence를 찾는 Dynamic programming Algorithm이다.


대략적으로 정리하자면 forward algorithm으로 대략적인 (어느정도 신뢰할만한) path를 형성하고 최종 형성된 path에서 다시 backward tracking을 하면서 가장 확률이 높게 나오는 이전 state를 선택해 가며 처음 상태로 되 돌아가야 최종적인 결과가 나오는 알고리즘이다.
forward만 고려할 경우, local 하게 maximum한 경우를 선택 하는 경우가 생길 수 있기 때문에 backward도 고려하는 것이다 때문에 viterbi algorithm은 가장 optimal한 path를 선택 하는 algorithm 이라고 할 수 있다.
따라서 HMM으로 모델링 된 어떤 문제에서 output sequence를 알면 대응되는 가장 probable한 state sequence을 알 수 있다.
그러나 아직, HMM으로 모델링이 안되어 있으므로 model parameter(초기값, aij, bij)를 모른다.
따라서 우리는 관측된 데이터(X)만 가지고 모든 상태전이확률,(aij) 생성확률(bij)을 잘 구할 수 있도록 모델구해야 하며, 이것이 지금부터 언급될 내용이다.
위에서도 언급했지만 보통 HMM의 파라미터 '람다'라 하면 아래 3가지를 의미한다.
1. 상태전이확률 : A
2. 생성확률 : B
3. 초기확률 : py
따라서, 람다 = ( A, B, py ) 이렇게 표현하고 실제 우리가 관측한 데이터를 X 라고 한다면,
우리가 만들려고 하는 어떤 모델은 '람다'를 조건으로 할 때, 관측 데이터 X를 가장 잘 표현해야 한다. 이런 종류의 문제는 Likelihood를 최대한 높임으로써 풀 수 있다.
likelihood에 대한 간단한 예로 동전 던지기를 들 수 있다.
우리가 알고 싶은 모델 파라미터 p가 동전을 던졌을 때 앞면이 나오는 확률이라고 하자.
관측 데이터 X는 실제로 동전을 던졌을 때 앞면 혹은 뒷면으로 확인된 값이다.
X가 1000개의 Sequence를 가져서 505번의 앞면과 495번의 뒷면이 나왔을 때 우리는 p를 가장 관측데이터에 fit하게 결정할 것이다. p값은 1이나 0이 아니고 0.5 값에 근접하게 맞춰갈 것이며 최종적으로 관측데이터 X에 가장 맞는 0.505를 구해 낼 것이다. 이러한 과정이 likelihood를 최대로 대서 모델 파라미터를 결정한다는 것이다. (예를 든 모델이 간단한 모델이어서 ML 과정이 필요 없다고 느껴지는데 실제 모델은 이보다 복잡하다)
우리는 likelihood를 최대화 하도록 람다를 학습 시켜야 하는데 이를 수식으로 풀어내면 다음과 같다.

P(X)를 위에서 언급한 것처럼 SUMMATION 형태로 바꿔 쓸 수 있다.

바꿔쓰게 되면, 뒷부분의 P(Q) 부분은 우리가 모르는 HIDDEN 이다. 다시말해 우리는 P(Q)를 Estimation을 해야 한다. 이 문제를 풀기 위해서 우리는 일반적으로 EM(Expected Maximization) 알고리즘을 사용한다. EM은 iterative 하게 Model을 training 하면서 최종적으로 likelihood를 극대화 하는 방법론이다.
( 위에서 기술된 Baum-Welch re-estimation은 EM 프레임웍을 HMM에 최적화시킨 알고리즘이다. )
정확한 수식은 이해하지 않았다. 대략적인 방식은 초기 모델 파라미터들을 랜덤하게 정한 뒤, observed sequence X={x1, x2,......} 로부터 모델 파라미터를 iterative하게 estimation 하는 방법이다. BW 다음과 같은 몇가지 문제들이 있다.

Overfitting의 문제는 주어진 observed sequence의 대표성이 부족한데 그러한 데이터를 가지고 iterative 하게 많은 learning을 시키면 오히려 learning 결과가 안 좋아지는 경우를 말한다. 이는 학습 데이터에 노이즈가 있거나 충분하지 못한 학습데이터를 이용할 때 일어 날 수 있는 현상이다.

위의 그림을 보면 EM 알고리즘은 Local maximum에 빠질 수 있다. (알고리즘의 구조상 hill-climbing과 비슷)
hidden markov model을 풀기 위한 전체적인 프로세스는 다음과 같다.
1. EM 알고리즘을 이용해 HMM을 학습시켜 model parameter 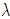 (초기값 , aij, bij) 를 구한다.
(초기값 , aij, bij) 를 구한다.
(초기값 , aij, bij) 를 구한다.2. Viterbi 알고리즘을 이용해, 가장 그럴듯한 state sequence를 찾아내는 것이다.
여기서 최종적으로 구하고자 하는 것이 hidden state에 대한 sequence를 찾아내는 것인데. 음.. 과정은 알겠는데 최종적으로 hidden state sequence를 찾아서 어디에 어떤 식으로 쓰이고 응용하는지 아직 감이 안 잡힌다.
Adaptive Probabilistic Visual Tracking with Incremental Subspace Update 논문에서 tracking 하고자 하는 object의 다음 위치를 예상할 때 hidden markov model을 사용했다. 본 논문을 읽으면서 다시 이해해 볼 필요가 있다.
댓글남기기