
Face Recognition based on PCA(얼굴인식)
이전 게시물 참고 : PCA(Principal Component Analysis)
LINK :
http://cheezestick.blogspot.kr/2012/09/pcaprincipal-component-analysis.html#more
4.2 Applicate to face recognition algorithm.
LINK :
http://cheezestick.blogspot.kr/2012/09/pcaprincipal-component-analysis.html#more
4.2 Applicate to face recognition algorithm.
1) 이미지들을 다음과 같이 읽어 저장 (총 20개의 training sample을 사용)

이미지가 112 by 92인데 이를 reshape해서 112*92 by 1로 만들어주고 이를 S에 쌓아 저장 결과적으로 다음과 같이 S는 112*92 by 20 의 데이터를 가지고 있음.


2) 이미지 각각의 mean과 standard variation을 구함
3) 이미지를 다음과 같이 normalize 해준다.
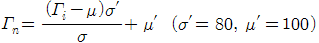
normalize해줌으로써, 사진들의 히스토그램을 평활화 하는 효과를 얻을 수 있다. 전체 샘플에 대해서 일정한 밝기의 정도를 가지게 해주며 대비차를 조절해준다.

4) 평균 얼굴 이미지를 구한다.


5) covariance Matrix
5-1 공분산(covariance)
covariance란 두 확률 변수 X,Y가 있을 때 각각의 확률변수와 그 평균과의 편차를 서로 곱한 결과에 기대 값을 취하는 것.
즉 공분산은 두 확률변수의 연관성을 나타낸다.
공분산은 다음과 같이 정의 된다.

5-2) covariance Matrix를 정의


로 부터
20개의 이미지들 서로간의 관계를 나타내는 20X20 covariance Matrix를 얻을 수 있다.
즉, A가 20 X 10304 행렬이고 A의 row 성분이 이미지를 구성한다고 하면,
AA' 는 20 X 20의 covariance matrix를 생성한다.
엄밀히 말해, 이는 10304로 나눠주지 않았으므로 스케일(lamda)이 10304배 만큼 크다고 말할 수 있으므로 AA'는 정확한 covariance matrix라고 할 수는 없지만
AA'로부터 구해진 eigenvector는 실제 covariance matrix와 동일하고, eigenvalue값만 A의 column 배 이다.
그러나 스케일은 중요하지 않다.
4.에서 보았듯이, PCA의 특성상 eigenvalue값이 클수록 중요도가 크기 때문에 내림차순으로 정렬하여, 중요한 eigenvector들을 이용한다.
따라서 eigenvalue 즉, 스케일 값은 중요치 않으므로 covariance matrix를 AA'로 정의해도 무방하다.
이렇게 구해진 covariance matrix에서 eigenvalue와 eigenvector를 구한다.
eigenvalue 순서대로 높은 중요도 순으로 20개의 eigenvector를 나열 할 수 있다.
이러한 eigenvector와 이미지를 곱하게 되면 PCA Face recognition에서는 이를, eigenface라고 한다. 이 값들을 이미지화 해서 나타내면 다음과 같다.

이는 training image 20개들이 가지는 공유하는 보편적인 성질(?)들을 중요도 순으로 가시화 한 것이다. 따라서 주어진 training image들은 저 20개의 eigenface들의 조합으로 표현 할수 있을 것이다.
6) Find the weight of each face in the training set eigenface들이 training image들에 각각 어느정도의 weight를 갖는지는,
이미지와 eigenface를 내적해 나타낼 수 있다. 두 이미지간의 vector의 성분이 일치하면 값이 1이 되어 최대 값을 가지게 될 것이고, 서로 다를수록 값이 작아 질 것이다.
7) Input image and recognition
일단 input 이미지가 다음과 같이 들어오면,

이 입력 영상도 과정 6)에서처럼 각각의 eigenface들의 weight 값을 구한다.
그리고 이 weight vector 값과 과정 6에서 구한 training image에 대한 eigenface weight값과 비교 한다.
비교는 Euclidean distance를 구해서 가장 짧은 거리 차를 가진 이미지를 가장 유사한 이미지라고 판단한다.
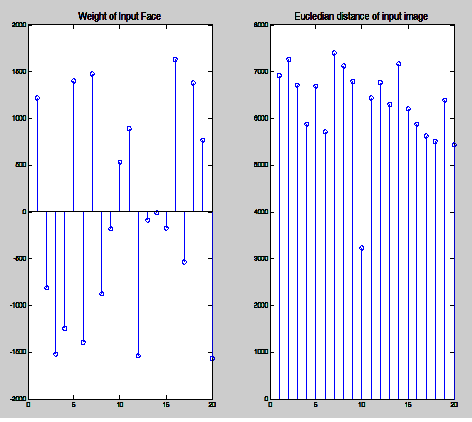
오른쪽 그래프를 확인하면 10번에 해당하는 training image가 input 이미지와 가장 유사함을 알 수 있다.
댓글남기기